




















.svg)
 Healthcare
Healthcare Finance
Finance Retail
Retail SaaS & Digital
SaaS & Digital eCommerce
eCommerce Education
Education

 Salesforce
Salesforce  HubSpot
HubSpot Pipedrive
Pipedrive Mailchimp
Mailchimp Zendesk
Zendesk  Freshdesk
Freshdesk HelpScout
HelpScout  Front
Front Slack
Slack  Zoom
Zoom Google Sheets
Google Sheets  Zapier
Zapier  Integrately
Integrately Webhooks
Webhooks  Blogs
Blogs Webinar
Webinar Product Updates
Product Updates



TL;DR
- Unify all feedback sources into one place before organizing anything
- Pass contextual attributes (plan, role, tenure) to every response for meaningful filtering
- Auto-tag and categorize using a 3-level taxonomy: type, product area, and severity
- Prioritize by impact and account tier, not just volume; three enterprise accounts beat fifty free users
- Route automatically: bugs to engineering, detractors to CS, feature requests to product
- Follow up based on response type: detractors, passives, and promoters need different messages
- Close the loop publicly: tell customers what changed because of their feedback
- Pick a tool that handles the full system, not just collection
In 2017, Zendesk shipped a chatbot called AnswerBot. Within two years, it had fundamentally changed how their support team handled inbound queries. Not because it was sophisticated. Because it pointed at the right problem — customers asking the same questions over and over, with no system catching that signal before it became noise.
Around the same time, HubSpot launched an ideas forum. Customers could submit feature requests, vote on each other's ideas, and see exactly where a request sat in the pipeline. What had been a chaotic stream of "can you add X?" emails became a structured, prioritized queue. The product team could filter by votes, by plan tier, by feature area.
Two different companies. Two very different approaches. The same realization underneath it all: collecting feedback is the easy part. What happens after it lands is where most teams fail.
You're probably already collecting. Surveys, support tickets, in-app prompts, review sites. The responses are coming in. But they're scattered, untagged, living in different tools, and nobody has a clear system for deciding what to act on first.
This guide is about building that system, step by step, using approaches from companies that have run it at real scale.
Step 1: Unify all your feedback sources before you try to organize anything
The first mistake most SaaS teams make isn't in how they organize feedback. It's that they try to organize it while it's still sitting in six different places.
NPS scores live in your survey tool. Churn reasons sit in CRM notes. Bug reports surface in Slack threads. Feature requests arrive by email. Support escalations pile up in Zendesk. App store reviews go unread for weeks. Each one gives you a fragment. None of them give you a pattern.
The four sources that matter most for SaaS products:
- Structured surveys: NPS, CSAT, and CES at key touchpoints: onboarding, post-feature adoption, renewal, and cancellation
- Support tickets: unfiltered, real-time signal on what's actively breaking and frustrating users
- In-app and digital feedback: in-product widgets, feedback buttons, and exit prompts that catch friction exactly when it's happening
- Review platforms: G2, Capterra, and Trustpilot for unprompted, public-facing opinions
The goal isn't to collect from more places. It's to pull everything into one system where you can tag, search, and filter it together. A support ticket that says "the export is broken" and an NPS open-text comment that says "your export feature is a nightmare" are the same signal. You'll only see that if they're in the same place.
Your customer lifecycle segments matter here too. New customers flag onboarding friction. Active customers surface usability gaps and missing features. Inactive customers show you where engagement collapsed. Churned customers tell you what you failed to fix before they left. Different signals, but they all belong in the same system, tagged by segment so you can read each group's feedback separately.
Step 2: Pass contextual attributes to every feedback response
Raw feedback without context is almost useless for prioritization.
"Your dashboard is confusing" means something different coming from a day-three trial user than from a two-year Enterprise customer on your highest plan. Same words. Completely different urgency and completely different implications for what to build next.
Attribute passing fixes this. When a user submits a survey response, your feedback platform silently enriches that response with backend data: subscription plan, lifecycle stage, account size, user role, and region, without asking the user anything additional. They fill out the survey. You get the response with full context attached.
The attributes that matter most for SaaS teams:
- Subscription plan: separates free-tier noise from paid-tier priorities
- Lifecycle stage (trial, active, at-risk, churned): reveals timing patterns in satisfaction scores
- Tenure or days active: shows how experience level shapes feedback content
- User role (admin, viewer, end-user): different roles have genuinely different pain points
- Region: relevant for multi-market products, support quality, and localization
Salesforce passes enriched account history and past interaction data to their support teams before they ever read a ticket. Slack routes team size, industry, and region to their product team so they can weight feedback from high-engagement segments differently than feedback from peripheral ones.
When you layer these attributes on, filtering becomes genuinely powerful. If your Enterprise plan NPS is 62 and your Starter plan NPS is 28, those are two different product problems, not one disappointing average. You'd never know that from a raw score.
This context layer is also what transforms a response inbox into something that resembles a real SaaS Feedback Management system. Without attributes, you have data. With them, you have signal.
Step 3: Categorize and tag incoming feedback automatically
Manual categorization at scale doesn't work. That's not an opinion. Atlassian proved it empirically.
At peak, Atlassian was receiving 15,000 pieces of customer feedback every week. They tried to sort it manually. It was error-prone, inconsistent, and slow. The kind of slow where a critical bug report sat unseen for days because no one got to it in the queue. So they built an automated classification system using machine learning, organizing every piece of incoming feedback into a three-category taxonomy they called RUF: Reliability, Usability, and Functionality.
The result: 15,000 responses categorized in a fraction of the time it had taken to process a tenth of that volume.
You don't need an ML model to get most of that benefit. You need a clear taxonomy and auto-tagging rules. Here's a three-level structure that works for most SaaS products:
- Level 1: Type (what kind of feedback is it?)
- Bug Report / Feature Request / UX Issue / Billing Question / Compliment
- Level 2: Area (which part of the product does it touch?)
- Onboarding / Dashboard / Reporting / Integrations / Billing / Mobile
- Level 3: Severity (how urgent is this?)
- Critical / Moderate / Minor
Level 1 + Level 2 covers 80% of your triage decisions. Level 3 feeds directly into the next step. A Critical Bug in Onboarding is a different beast from a Minor UX Issue in Reporting, and your team shouldn't need to read the response to know which is which.
Most feedback platforms let you define keyword triggers that apply these tags automatically. A response containing "broken" or "error" or "not loading" gets tagged Bug + Critical. One with "would be great if" or "feature idea" gets tagged Feature Request + Moderate. You set the rules once. The system applies them continuously, whether you get 50 responses a week or 50,000.
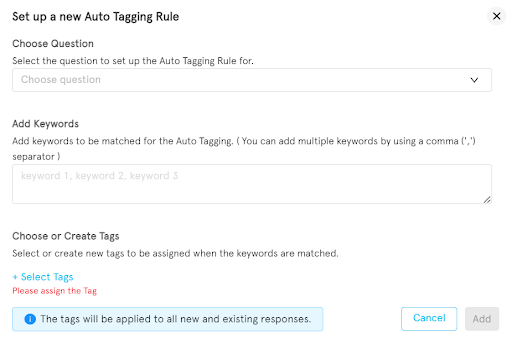
Auto-tagging rules in Zonka Feedback: keyword triggers assign tags automatically across type, area, and severity.
Step 4: Prioritize by impact and account tier, not just volume
Here's where most teams go wrong. Fifty users asking for Feature A doesn't automatically mean Feature A goes on the roadmap next.
If those fifty users are on your free tier and three Enterprise accounts have separately mentioned Feature B (not fifty times, just three), Feature B probably carries more business impact. Frequency is a real signal. But frequency without segment context leads you to build for the wrong people.
A simple two-dimension framework cuts through this:
| High Frequency | Low Frequency | |
| High Impact | Fix now. Drop everything. | Plan for roadmap. High-value signal even if rare. |
| Low Impact | Monitor. Real pattern, not urgent. | Deprioritize. Noted, not acted on. |
Impact means: revenue risk, retention risk, account tier, or feature criticality for the segment that needs it. Frequency means: how many distinct users or accounts have raised it (not total mention count).
The attribute data from Step 2 makes this framework usable. When you know a request comes from 12-month Enterprise customers with high usage scores, a frequency of three outweighs a frequency of thirty from free-tier day-one signups. The attribute layer is what lets you make that call without guesswork.
Recency matters too. A complaint pattern that appeared in 12 of the last 20 NPS responses is more urgent than one mentioned 40 times eight months ago and now quiet. Either the problem got fixed, or users adapted. Either way, it's not your top priority today.
Atlassian's RUF framework effectively embedded a version of this logic. Reliability issues (affecting stability, trust, and renewal rates) were structurally weighted above usability issues by default, regardless of raw ticket count. They built the prioritization bias into the taxonomy itself.
Step 5: Route feedback to the right team automatically
Once you've tagged and prioritized feedback, it needs to reach the right person. Without routing automation, that hand-off still requires a human to read every tagged response and decide who handles it. That's the bottleneck where most feedback goes quiet.
HubSpot's workflow is a clean model here. When a user submits a feature request for one of their products, an automated notification goes directly to the product team responsible for that area. The team reviews it and makes a call, but they're not discovering it by accident three weeks later. The system brought it to them.
A routing matrix for most SaaS teams looks roughly like this:
| Feedback Type | Route To | Timing |
| Bug Report (Critical) | Engineering via Jira ticket (auto-created) | Immediate |
| Feature Request | Product Manager | Email + weekly digest |
| NPS Detractor (0–6) | Customer Success | Alert within 24 hours |
| Pricing complaint | Sales / CS for retention | Immediate if at-risk or churned |
| NPS Promoter (9–10) | Marketing for reference outreach | Weekly batch |
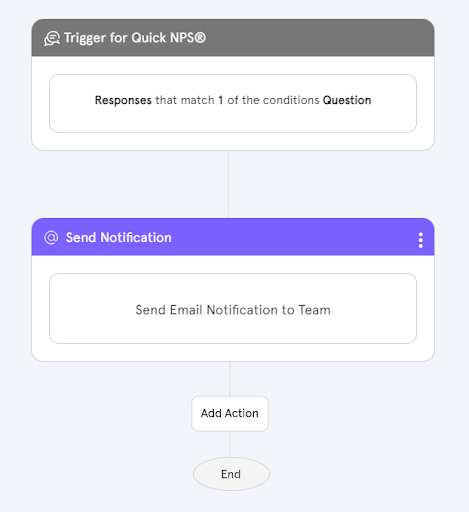
Workflow automation in Zonka Feedback: trigger-based routing sends the right feedback to the right team, automatically.
Zendesk, Jira, Slack, HubSpot, Salesforce: your feedback platform connects to them via native integration or webhook, and the routing trigger fires automatically based on the tags and priority scores assigned in Steps 3 and 4.
What makes this work isn't the automation itself. It's the consistency. When every detractor response triggers a CS alert, the CS team learns to expect it and respond within the window. When every critical bug auto-creates a Jira ticket, engineering doesn't depend on someone remembering to file it. The system eliminates the human hand-off — which is exactly where follow-through tends to collapse.
Step 6: Follow up with customers to acknowledge their feedback
Front, the customer communication platform, has been public about one of their principles: "We suggest the ideas we feel most strongly about and let our users tell us what really clicks with them." What makes that work is that they close the loop, and users who submit feedback actually hear something back.
Autoresponders don't replace that relationship. But they do the first job: signal that someone received the feedback and that it matters.
A simple follow-up framework by response type:
- Detractors (NPS 0–6): Acknowledge the frustration within 24 hours. Don't explain or defend. Ask one specific clarifying question about the pain point: what made it a 3 instead of a 6, for example.
- Passives (NPS 7–8): Thank them. Ask what would have made the experience a 9 or 10. Passives are the most underused segment. They're not angry enough to churn but not satisfied enough to stay. They have the clearest picture of the gap.
- Promoters (NPS 9–10): Thank them and invite them into something: a public review, a beta group, a reference conversation. This is warm ground. Don't waste it on a generic "thanks for the feedback."
For CSAT and CES responses, the same logic holds. Low score: acknowledge and clarify. High score: thank and activate.
One caution: the first touch can't sound automated. A message that opens with "Hi [First Name], we received your feedback and appreciate your time" is technically an autoresponder and unmistakably so. The response that actually lands is the one that references something specific from what they said, because someone should have read it before the message went out.
Step 7: Close the loop — act, then tell customers you did
Slack retains 90% of free users and 98% of paid users. Part of that is product quality. But part of it is operationally intentional: Slack maintains a public roadmap where users can track exactly what's happened to their feedback. Not just "we're considering this." Actual shipping notes, status updates, and explicit acknowledgments of what changed because users asked for it.
That's a high bar. But the principle scales down.
Closing the feedback loop means two distinct things:
- Internal closure: the feedback triggered a decision (build it, deprioritize it, investigate it, or document why you won't build it), and that decision is recorded and traceable to the original response.
- External closure: the user who gave the feedback knows something happened because of what they said.
Most SaaS teams do the first one inconsistently and skip the second almost entirely. That's why customers report that feedback "disappears into a void," and operationally, it often does.
A practical external closure playbook:
- When you ship a feature that was frequently requested, include a note in the release announcement that it came from user feedback. Specific numbers land better: "62 of you asked for this in NPS surveys over the past quarter."
- When you can't build something, send a short honest note explaining why. Users respect a real "we decided not to prioritize this because X" over silence.
- When satisfaction scores improve significantly after a product change, share the before/after data with the users who participated in the measurement. It closes a circle most companies leave open.
SmartBuyGlasses, a global eyewear e-commerce retailer operating across 30+ countries, increased their NPS by 30% after implementing a structured feedback loop. Not by collecting more feedback, but by systematically acting on it and communicating what changed to users. The collection was already there. The closure was what moved the score.
Step 8: Choose a tool that handles the full system, not just collection
Most feedback tools solve one part of the problem well. They collect well. Or they analyze well. Or they have strong reporting. Very few handle the full arc: from multi-source collection through categorization, routing, and closed-loop resolution.
When you're evaluating tools, four criteria matter most for the system described above:
- Multi-source unification: Can the tool ingest data from surveys, support tickets, review platforms, and chat transcripts together, or is it limited to surveys it sent itself?
- Auto-tagging and AI categorization: Does it support keyword-based tagging or AI-assisted thematic clustering? Can you define a custom taxonomy, or are you locked into theirs?
- Routing integrations: Does it connect natively to Jira, Zendesk, Slack, and HubSpot? Can you configure routing rules and workflow triggers without engineering support?
- Loop closure capabilities: Does it track resolution status per response? Can it trigger follow-up messages automatically based on score or tag?
There are solid SaaS Customer Feedback tools for each of these individually. The friction is consolidation. Every additional tool in your feedback stack adds a handoff, and handoffs are where signals go quiet.
Zonka Feedback covers all four: multi-source unification across surveys, tickets, reviews, and chat; AI-assisted thematic analysis with entity mapping across your specific locations, agents, and product areas; native integrations with Jira, Zendesk, Slack, HubSpot, and Salesforce; and automated loop-closure workflows with per-response resolution tracking. If you're currently stitching three tools together to get what one system should handle, it's worth seeing where the stack consolidates.
Zonka Feedback covers collection, categorization, routing, and loop closure in a single platform.
Conclusion
When feedback starts coming in, the instinct is to read it. All of it. Find the patterns manually, flag things in Slack, build a list of "things users want." That works for a while.
Then volume hits. Or competing priorities stack up. Or the person doing the reading moves on, and the institutional knowledge goes with them.
A working feedback system isn't about working harder at the reading. It's about a reliable chain: feedback arrives, gets tagged, reaches the right person, priority is clear, the customer hears back, and the roadmap reflects what you learned. Build that chain once, and it runs, whether your team is reading responses or not.
See how Zonka Feedback handles the full system: from collection to closed loop.
Schedule a demo














